Beep boop - this is a robot. A new show has been posted to TWiT…
What are your thoughts about today’s show? We’d love to hear from you!
Beep boop - this is a robot. A new show has been posted to TWiT…
What are your thoughts about today’s show? We’d love to hear from you!
This is surely a sign of the end times of tech… today’s announcements felt like the most incremental they could possibly be. ![]()
I agree the announcements felt incremental but still good improvements for the most part. The iPhone Air might be a bit of a departure with the ultra thin design and placing the processor under the camera “plateau”. It makes me wonder if these features might be important for a future folding phone. I guess we will see in the next year or two!
The changes in the base 17 are pretty good though, finally a ProRes 120Hz display, double the storage and a decent camera upgrade… It pretty much makes the Pro redundant for most people, I would think, only those that need the extra camera will really need to go with the Pro this time round.
I didn’t watch MBW yet, but I ordered myself new AirPods Pro. I’m excited about the USB-C and heart rate monitor. My current AirPods Pro are still great, but the case sucks. I find myself charging it if nit everyday, every other day.
I’m glad I don’t need or want an iPhone this year. The orange Pro looks yummy but I don’t like thst the Pro device went back to aluminum; they look & feel(not literal feel. I know it has glass on the back so it’ll feel different) like an iPhone 6 Plus.
The base iPhone is also really good this year, except for me: I use the telephoto camera a lot. and I couldn’t live without it now. Speaking of which, I think changed the Telephoto camera from s 5X, to a 4X but with s digital crop up to 8X… which makes me feel weird
the Apple Watch intro video made me tear up.
Andy’s Apple Watch Actout was really funny
I don’t really love Apple flip flopping on finishes. I always liked the polished stainless steel look. I adjusted to the brushed titanium but I always felt like I was missing the jewellery look of the shiny phones. It’s nice that the Air looks shiny & polished again but I’m still kind of annoyed what they did to the Pro phones. I know they say it was for thermals but I cannot help but feel like it’s a cost saving measure. Specially given they touted they’re using less materials on these new phones
The colours of the iPhone 17 aren’t for me. the 16s were sooooo gorgeous
I always buy the base storage on my devices. I’ve only ever ran into storage issues on 1 iPhone: my first one/. 10 years ago I was using a 16GB iPhone 6S Plus. Facebook & Instagram as apps have a tendency to balloon up to 1GB+ in size. So much so that I actually stopped using those apps (instead using the websites) up until 2-3 years ago. I only use 115GB on my iPhone currently.
There was no doubt in anyone’s mind whether Leo would be getting this new phone
The improvement of the A19 GPU speed is 20%, 80%, 90%, and 200% faster for upgrades from the iPhone 16, 15, 14, and 13 (slide at 34:00 in Apple Presentation). That’s an incremental improvement from 1-2 years ago, but a quantum improvement from 4Y ago. You see similar improvements in the CPUs and the Neural Processing Units.
Relocating most of the circuitry to the top 20% of the iPhones is a pretty complete re-design of the wiring of all models. This allows for simplification of the layout, more effective cooling, and larger batteries of the Pro model. It also allows for the dramatic thinness of the new iPhone Air.
The Air looks like a bold design choice. Its Apple C1X cellular modem chip provides energy-efficient performance and should pave the way for moving away from Qualcomm in 1-2 years. And note the deployment of the N1 chip for WiFi, Bluetooth, and Thread in all iPhone models this year. This was the first appearance for the N1 chip anywhere; Apple was clearly confident that its deployment would be smooth. Apple could roll the N1 and C1X chips together for a single chip providing all communications for iPhones and iPads – and maybe Macs.
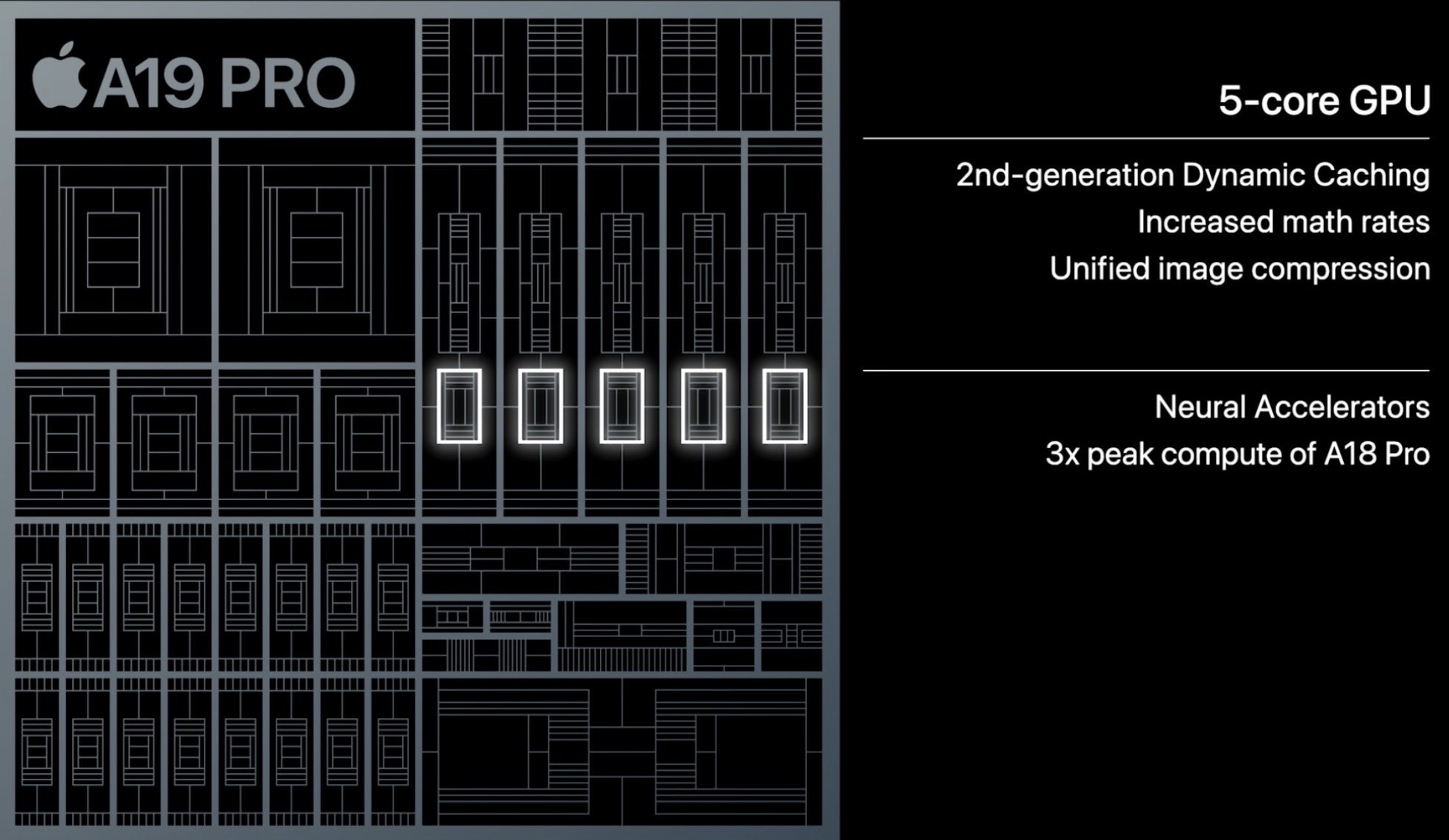
The addition of Neural Accelerators in the A19 Pro GPUs is a big thing for running LLMs locally. They allow matrix multiplications much more efficiently inside of the GPU – a processor within a processor. NVIDIA has had sub-processors embedded in their GPUs for many years; they call them Tensor Cores. It’s a near certainty that Apple’s Neural Accelerators will be included in the GPU of M5 processors. They will make a huge difference in both the speed and efficiency of both training and running LLMs.I pity the fools who bought those $10K M3 Ultra Mac Studio machines loaded with 512GB of unified memory; the M5 Studio generation will be a massive improvement over those models.
Apple Health has created a novel way to detect hypertension with the Apple Watch. There is a chronic lack of awareness about high blood pressure; that is a real gift to the ~1M people who may get that warning in the next year. Nobody’s ever done that before. Apple is now looking inward to monitor the hard pulse rate with IR detectors. Health-monitoring with instrumentation in wearables will continue to expand in the future.
Improvements in iPhone processor speed are small from last year, but the compounded speed improvements from products 3-4 years ago are huge. For the majority of customers, improvements from a typical purchase cycle are quite large. I predict the sphere of Apple Health coverage will be unrecognizable 4-5 years from now.
I don’t score this as the most incremental of improvements. YMMV.
Apple’s “Catch up Quick” video released on Tuesday looks and sounds like Serenity Caldwell. Its 154-second summary of the 9/9 presentation is a tight edit and is quite funny. The video appears to be a commentary on the “Everything Apple announced in 6 minutes” videos. Highly recommended whether or not it’s Ren.

I just gave in and ordered myself a new Apple Watch. I’ve been using a Series 6 on and off ever since it came out. This year I fell back in love with the device because I started running without my iPhone. It’s also nice to go for walks without the iPhone.
I am considered returning the AirPods (as it’s too late to cancel) and buying a new pair when I need them, as a JIT purchase instead of just giving into consumeristic greed before I “absolutely need” a new pair. I do know I’ll enjoy & benefit from them though. The voice of my therapist echo’s in my head (perhaps incorrectly) telling me it’s OK to spoil yourself sometimes.
Lime green is my favourite colour.
The YouTube Algorithm just put Demystifying Apple’s AMX AI accelerator: when and why it outperforms the GPU in my video feed: https://www.youtube.com/watch?v=TjfA9LVgHXk . This is an excellent video showing the history of Apple’s specialty matrix-multiply hardware – which has actually been around since M1 processor (discussed at ~2:00 into the video). These AMX accelerators have rarely been discussed in Apple’s technical presentations. @5555:14 the presenter “Peter Tech” notes:
The ability to perform that many more operations with the same amount of data is critical to reducing the energy consumption of a computational device. Because nowadays, the energy needed to transfer data significantly exceeds the energy needed to perform computations on the data.
An outer product is a way of multiplying two vectors that produces a matrix. The idea is to multiply every number in the column vector A by every number in the grow vector B.
One way to do that is to take the first number of B multiply every number of A. This becomes the first column of the result matrix. We repeat the same with the second number of B to produce the second column of the result matrix and likewise with the third number of B. The outer product way of multiplying matrices is unlike what is typicall taught in school where each element the result matrix is computed by multiplying a row in Matrix A with a column in Matrix B. In other words, the multiplication of two vectors produces just one value. This is highly inefficient because we would be reading the same columns over and over from memory.
With the outer product way, we load a column of A and a row of B only once and compute the matrix of results instead of a single value. It works as follows:
- Take each column of A and pair with the matching row of B.
- Compute their outer product, the result of which is a matrix.
- Sum or accumulate the three resulting matrices to complete the matrix multiplication.
It takes three cycles to multiply a 3x3 matrix this way. Apple’s outer product engine accelerates the outer product calculation and the matrix accumulation.
Here are 2 slides from the presentation. Peter uses animated graphics perfectly in the video; it’s pretty easy to understand the single memory access of the cells to render the entire matrix multiply. It works better in his video than my text commentary.
I knew that someone out there would have a presentation about these elusive matrix multiply co-processors. These look like a keystone of having LLM interactions be both fast and energy-efficient on user devices – and probably also for the training of devices. I know very little about how comparable silicon elements work from NVIDIA’s design (and others). That would be a most interesting question!
I had been wishing for someone to explain this to me. I feel.. lucky… that Google read my mind and served up the perfect video to explain this idea. It’s simultaneously very satisfying and somewhat creepy. @Leo : this may a good person to have as a guest on MBW or some other show during the summer doldrums that are starting about now. #getyourinnergeekon
Apple has done less than perfectly in some of their AI development. OTOH, they appear to be hitting it out of the park with their matrix-multiply accelerators: a key feature for having the AIs run well. It’s interesting that this key feature has gotten so little attention.
This is a line in the sand of the AI revolution. I’m guessing the 512GB M5 Ultra Mac Studio will be an incredible workhorse for both training and running LLM models starting in early in 2026 – orders of magnitude better than the loaded M3 Ultra version of this workstation.
Again, I think the deployment and API exposure of the AMX matrix accelerators are a huge improvement in the A-series processor architecture – and will be a huge improvement in the new M-5 processors to come. IMHO, history will view this as a keystone improvement.
This is, as ever with Apple, reality distortion field. They’re a huge improvement for Apple, but they’re just Apple catching up to the pack. I asked ChatGPT to unwrap the hype and here’s its summary:
🧮 The Matrix Multiply Reality
Matrix multiplication (GEMM ops, for example) is a core primitive in:
Deep learning (forward and backprop)
Physics simulations
Graphics (e.g., transforms, projections)
GPUs have specialized hardware for this — NVIDIA’s Tensor Cores since
the Volta architecture (2017), and AMD's equivalent in newer architectures
like RDNA 3. These units are orders of magnitude faster than CPU-based math
for matrix operations.
So Apple’s AMX units are not a new idea — but:
They're tailored for Apple’s ARM architecture and unified memory model
Optimized for power and thermal constraints in mobile/desktop SOCs
Integrated tightly with Core ML and their custom AI stack
🔍 Translation of Apple's Marketing
When Apple says something like:
“Our new matrix multiply units offer groundbreaking
performance for machine learning workloads.”
A more accurate, engineering-style phrasing would be:
“We’ve implemented hardware-accelerated matrix multiply
instructions (AMX) and improved them across silicon generations,
achieving high performance-per-watt for common ML operations,
comparable to (but not beating) dedicated ML accelerators in GPUs.”
Whoa! The point was that Apple A19 Pro chip AMX matrix accelerators are a huge improvement over Apple’s previous implementations. That is not a distortion; it is rooted entirely in reality. It was actually in response to a comment made earlier in this discussion:
I disagree: adding matrix multiplication efficiency to this architecture was a huge improvement. Individual users and the planet will benefit from that performance increase.
For me, the key comment from the video was that [inefficient] memory accesses consume more power than the actual computation in contemporary processors – the value in performing all matrix multiply accesses as atomic actions. This is a huge departure from the way computers were designed in the 20th Century. At this point in time, a principal limitation in architecture is the imagination of the designers.
I’m also gobsmacked that the matrix multiplier units keep popping up at different geographic locations in the processors. Earlier generations had them logically discreet near the [high-performance] CPUs. This generation has them embedded in the GPUs. I could see advantages to this new location: fetches of the block of data constituting a matrix could be streamlined to increase their fetch/store speed. With their large number of GPUs, large M5 Pro/Max/Ultra architectures could be monster matrix manipulators. Apple may never be favored by other companies for AI server farms, but new high-end Macs will be great for individual researchers and business.
I want to see all new computers be as efficient as possible for creating and running LLMs. Any efficiency that any manufacturer brings to the process is welcomed. I’m pretty sure that YouTube blogger Petar shares that opinion.
If you’re going to introduce an AI answer to a discussion, please include the prompt that you used to generate that response. Most AIs have a “share” button for exactly that purpose.
This YouTube blogger serves up interesting videos – good or bad. Note his video Is this why Apple did not come out with an M4 Ultra: Mac Studio M4 Max consuming over 330W!!! . He’s blasting the M4 for its excessive power usage and thermal throttling; he speculates that the never-released M4 Ultra Mac Studio could not even function in the thermal envelope of the Mac Studio hardware. These are not the actions of an Apple fanboy. Associating this fact-based blogger with the pejorative “reality distortion field” makes no sense. That dog don’t hunt. ![]()
i love your way with words
You just made that association, not me. I used it to complain about the habit of Apple Marketing to make everything that Apple markets seem like Apple is the only one who could ever do whatever it is they’re crowing about. They like to try and pretend they invented everything and before they did it was unimportant or unimpressive. Yes, Apple does make some reasonably okay products… but they are in no way any more special than any other PC or cell phone on the market EXCEPT for how they’re marketed and how the fanbois eat it up. As I am not a fan of Apple, I call it as I see it… hype piled on more hype from Apple’s hype based marketing team.
Sorry. It looked like you had a specific complaint. We couldn’t tell who or what you were complaining about.
What specifically is your complaint about the announcement of Apple A19 Pro chip AMX matrix accelerators? In other words, what was your prompt to ChatGPT that generated the response you posted here? There was a point to that question. Can you answer it now?
The only commentary I’ve seen from that Cupertino’s dastardly field-creating fount of reality-distortion was VP Tim Millet’s commentary from the September 9 event (full transcript here):
We have been at the forefront of AI acceleration since we first introduced the neural engine eight years ago. We later brought machine-learning accelerators to our CPUs. And while our GPU has always been great at AI compute, we’re now taking a big step forward, building neural accelerators into each GPU core, delivering up to three times the peak GPU compute of A18 Pro. This is MacBook Pro levels of compute in an iPhone, perfect for GPU-intensive AI workloads.
One might quibble over Tim’s use of the word “great”, but there’s not a hemidemisemiquaver of reality-distortion there. Just like Petar’s great video, Tim’s brief presentation on the A19 Pro architecture is rooted in cold hard facts. One is left with a delicious question: if the A19 Pro is giving us “MacBook Pro levels of in an iPhone,” then what the heck will M5 MacBook Pros be like when using this technology?
The M5 MacBook Pros are going to be impressive. What PCs do you predict will have a superior performance at the same levels of energy?
Please show us what prompt you used to generate the exact ChatGPT answer you posted here. Thanks, Paul.
As ever, you twist and turn your point with every post. I’m not interested in playing that game with you. I stand by what I said. Apple’s latest event was a yawn-fest and they’re stuck on incremental “innovation” like making the display harder to read with “liquid glass” and making a thinner phone with a cancerous bump and worse battery that no one was begging for.
As for how I use ChatGPT, that’s my business and not yours. You can make your own prompts as easily as I can make mine. More specifically, I don’t pay for ChatGPT and use it free without an account, so I have no history to go back to to get the prompt even if I wanted to.
Isn’t that the main purpose of Marketing ![]()
Probably yes, but Apple fans seem drink more of the Koolaid than most? ![]()
The phrase “Kool-Aid” implies there’s something delusional about Apple Marketing [with the A19 and A19 Pro iPhone models]. We don’t have to worry about an alleged reality distortion field or any imbibing of powdered sugar beverages. We can look at the actual results: what factually happened in the quarter after this product announcement. Here again is VP Tim Millet’s specific commentary about the neural accelerators of the A19 Pro chip:
We have been at the forefront of AI acceleration since we first introduced the neural engine eight years ago. We later brought machine-learning accelerators to our CPUs. And while our GPU has always been great at AI compute, we’re now taking a big step forward, building neural accelerators into each GPU core, delivering up to three times the peak GPU compute of A18 Pro. This is MacBook Pro levels of compute in an iPhone, perfect for GPU-intensive AI workloads.
These neural accelerators all A19 Pro iPhones (iPhone Air, iPhone 17 Pro, iPhone 17 Max). Apple experienced its greatest quarter ever in Q1 2026 (September 28, 2025 to December 27, 2025), with $85.3B in iPhone revenue in the quarter – $937,362,637 in iPhone revenue per day. That blew the doors off of everything that Apple or any competitor ever did. That was an epic result! As the newest MBW panelist Christina Warren noted in MBW #1014 at 5:49, these new iPhones have best-in-class processors.
Apple has since used that same accelerated matrix-multiply circuit in every GPU in the M5 machines: 8/10 in laptops with M5 chip; 16/20 in laptops with the M5 Pro Chip, and 32 in the M5 Max Chip. All the CPUs, GPUs, and NPUs have unified access to main memory, and the Metal API provides a universal platform to accessing that power from iPhones to iPads to MacBooks to the Mac Studio.
What phones had anything comparable to Apple’s Q1 2026 results? What vendor supplies universal access to develop and access the variety of processors in these chips? Nobody. Nobody even came close.
Is it really appropriate to call these new iPhone improvements “the most incremental they could possibly be”? Is it really appropriate to say, “This is, as ever with Apple, reality distortion field.” The result of $85.3B in iPhone sales in one quarter (!!!) respectfully disagrees.
This was factually incorrect. You simply need a login with ChatGPT to maintain and access your history of conversations. Dittos with Grok. Dittos with Claude.
The AVP was an example where the announcement hype did not match customer interest. At best, one could say that those goggles were released before their time; the reality did not match the hype. OTOH, these September announcements clearly delivered on their promises.
@floatingbones I’m not sure if you suffer from some sort of disorder that causes you to communicate improperly, but I’m not going to tell you this ever again, so make sure it sinks in: You don’t get to tell me (nor anyone else) how to exist. I FACTUALLY said I do not use an account. Sure I could use an account, but I do not, and will not. PERIOD. I really don’t care if this perturbs you.
No, actually that’s not how it works. The delusion, if you want to use that word, is how the the consumer behaves when they are overly influenced by the marketing. The marketing is designed in a specific way to influence specific users to feel the need to spend more money consuming more Apple products when the one they probably already have would probably still meet their needs adequately if they hadn’t experienced the marketing message(s). It’s been otherwise called the “reality distortion field.” It appears to work better on some people than others. Clearly it works better for you than it does for me… in fact where I am concerned, the more I see of Apple ads the less I like them as a company. (Not that this is particularly just an Apple effect, I feel likewise for many other companies, both large and small.)
As for the fact that Apple line must got up… this is not a new thing. Every time they bring new products to market, they get the die-hards who will buy it no matter what, and then they also get a certain percentage of their user base, probably about 1/3rd that replace their old thing with the new one on a regular cycle of approximately once every three years. (I’m not an expert on it, this is just my impression from outside observation.) Since the user base has generally grown (presumably as the population grows and they still maintain x% of them as their market share that means they will still get new sales to new customers) it means every year they should have more customers than the year before assuming all trends hold. It’d only be news worthy if there were a sudden spike beyond the normal trend, and I don’t believe there was any special spike recently.